
c-lightning v0.10.2 — “Bitcoin Dust Consensus Rule”

The c-lightning team is delighted to announce the release of c-lightning v0.10.2, the latest and greatest version of our Lightning implementation. This release had 333 commits by 19 contributors, and while this is just a minor version, the changes and improvements are all but minor.
Big Picture
There have been too many changes, both user-visible and internal, to list them all here, however we’d like to call out a couple of notable changes:
- Database size decrease: with nodes processing more and more payments some router operators have noticed that the database size can grow quickly, due to information associated with HTLCs. Rusty has built a pruning mode for HTLCs, storing just the minimal information required, which resulted in a 66% reduction in database size on his node.
- Payment history for multiple payment attempts: we now correctly track and display multiple payment attempts for the same invoice. Previously re-attempting would discard any prior failed attempt, but now you’ll see those attempts being grouped correctly.
datastoreAPI for plugins: the newdatastoreAPI allows plugins to persist data they need for their operations in the main database. This allows plugins to use the database instead of writing files to disk, which may be ephemeral, e.g., in dockerized setups.- Stale connection detection: on top of the already existing pinging of idle connections before sending a command, we now regularly ping peers to detect stale connections ahead of time, thus reducing potential issues when the connection is needed. This is particularly useful for Tor nodes, which can disconnect silently.
These and many more changes can be seen in the CHANGELOG.md. In the following we’d like to highlight one particular improvement introduced in v0.10.2: following the excitement around optimal flow computation we decided to take a first step in that direction, implement probabilistic route selection, and see if it improves the performance of our pay implementation.
Improving Pay Performance
The probabilistic route selection and optimal flow selection papers by Pickhardt et al. outline a two-step mechanism to compute optimal routes based on a probabilistic model of the network. The core idea being that larger channels would have to be much more imbalanced than smaller channels to be unable to forward a payment, and therefore they should be preferred. We implemented this in #4771 by experimenting with a variety of biasing functions, and found that the function proposed in the paper indeed outperforms the other variants.
Measuring Pay Performance
Before we can benchmark improvements to the pay plugin we first have to identify the key metrics that our users are interested in. Taking the perspective of the end-user and the network we came up with the following metrics:
- Success-and failure-rate: users are ultimately interested in making a payment, and if a payment fails, then that’s not a good user experience.
- Time to completion: waiting for your payment to complete is cumbersome, and we should always strive for the shortest possible time to get either a success or a failure. Nobody likes to wait in limbo.
- Attempts to completion: if we could just brute-force our way through the network, we’d likely get very good success rates, however attempting every possible route is slow, leaks a lot of privacy (both about the user’s intent and the channel balances in the network), increases the chances of having a stuck payment, and increases load on the network as a whole. The fewer attempts we perform before getting a final verdict, the better behaved our payment algorithm is.
As you can guess, these metrics are a tradeoff, for example if we were to allow as many attempts as we wanted to, then the time to completion and the number of attempts would suffer, in favor of the overall success rate. Nevertheless, by picking the routes we attempt carefully we can still get an improvement in all three metrics, providing an unequivocal improvement of the user-experience.
To measure these metrics we had to build some infrastructure. While in non-MPP payments a probe was sufficient to gauge the performance, in MPP payments we need the prospective recipient to collect all parts and report either success or failure for all parts combined, not individually. For this purpose we use the paytest plugin, which not only collects incoming parts, reporting the outcome, but it also allows us to generate normal-looking invoices on behalf of the recipient, cutting down on communication overhead. We then asked a number of intrepid community members to run the plugin and we could start testing the variants of the pay plugin.
How Well Are We Doing?
So now that we know how to compare the effects of the changes in the algorithm, let’s get to the actual results. We tested a total of 3 variants, each with several thousand payments to users of the paytest plugin, with a variety of amounts and at various times.
The following variants where tested:
baseline: this is the cost function used in v0.10.1, and does not take the channel size into consideration when deciding whether one channel is to be preferred to another.linear: this cost function simply divides the cost by the channel capacity, ensuring that, if all other parameters are equal, a larger channel will be preferred over a smaller one.logprob: uses the log probabilities from the model presented in the paper to compute a probability of a payment with a given size to be forwarded correctly through the channel.
First, the big headline numbers: our success rate went from 90.3% success, to 95.5% by switching from the baseline in v0.10.1 to a log probability based channel selection. In other words, we more than halved the number of failing payments! And this is without even optimizing the way we split payments yet.
For the other measurements, we need to go a bit into detail. For both time to completion and number of attempts, they depend on the amounts involved, since we don’t split below 10'000 sat by default, and we’ll try to split into equal sized buckets above that value. This can impact time to completion since we now have more attempts, and if only one of them is slow, the overall process is slow. Nevertheless, the new prioritization manages to lower both of these metrics considerably:
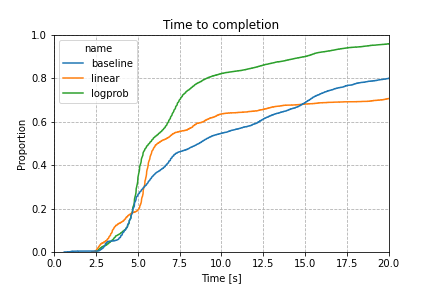
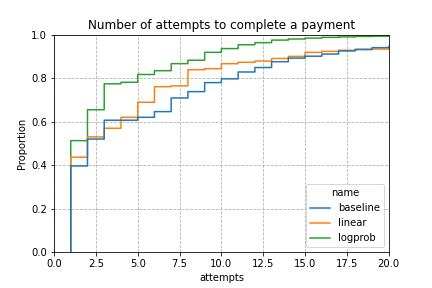
From the attempts plot we can see that both linear and logprob perform better than the baseline. With logprob just over 50% of payments complete with just 1 HTLC being sent, whereas the two other variants only complete around 40% with a single HTLC. Furthermore baseline and linear have a much longer tail, which can result in much longer wait times for unlucky payments, whereas logprob converges very quickly to 100% completion after 20 attempts.
For the time to completion, results are even more encouraging, with both new variants showing a considerable shift towards shorter times, and logprob beating all other variants with a much shorter tail, and quicker median time to completion. The median payment with baseline completes in 8.6 seconds, whereas linear improves the median to 6.2 seconds (however with a much longer tail resulting in a worse average performance) and finally logprob has a median of just 5.7 seconds, and the lowest average time to completion as well.
Disclaimer: Take these numbers with a grain of salt. While we tried to make our measurements as stable as possible, the network weather and our position in the network may have influenced them. We’re hoping that by adding more points of measurement, we’ll eventually be able to have a better understanding of the variables that affect our measurements.
Conclusion
This is just the start towards improving the performance, and we are looking into optimizing the parameters over time, and maybe implementing the full optimal flow computation proposed by Rene’s paper. #PickhardtPayments here we come 😉
As always, we’d like to know from users and node operators what their experience is, and we need your feedback to steer the direction of the project. Did you notice an improvement as well? Is there something that we could do better?
So head over to the c-lightning repository, update to the latest release, and enjoy! If you want to dig deeper into what our amazing contributors have done since the last release, check out the CHANGELOG.md for all the detailed changes.
And as always, a huge thanks to the contributors and volunteers that help make c-lightning better and better over time. 😃
Note: This blog was originally posted at https://medium.com/blockstream/c-lightning-v0-10-2-bitcoin-dust-consensus-rule-33e777d58657